
💡 좋은 모델 개발은 좋은 데이터에서 비롯된다.
아무리 좋은 알고리즘을 사용하고 갖은 노력을 들여도 데이터가 쓰레기면 결코 좋은 성능은 기대하기 힘들다.
Imputation
- 결측치(NA) 값은 머신러닝 모델 성능에 영향을 줌
- 70% 이상의 결측치가 있는 행과 열은 지워주는 것도 좋다
- Numerical Imputation (수치형 데이터)
- 결측치를 0 이나 중앙값으로 대체 - Categorical Imputation (범주형 데이터)
- 가장 많이 발생한 값으로 대체
- 아예 새로운 범주로 대체 - Random sample Imputation
-데이터셋에서 임의로 뽑은 값으로 대체 - End of Distribution Imputation
-mean(평균) + 3*std(분산) 으로 대체
- 결측치를 outlier(이상치)로 보냄
- 영향을 최소화 하기 위해서라면 오히려 보편적을 값을 사용하지만 결측치 자체에 특별한 의미를 부여하거나 이상치 후처리를 위해서 수행하는 작업이 아닐까라는 개인적인 판단
Outlier
- 평균적인 값보다 많이 동떨어진 데이터
- 대게 Boxplot 을 그려 파악
- 모델에 따라 민감도 다름 (모델에 따라 이상치를 포함할지 제거할지 조정할지 정함)

표준편차 이용
- 값과 평균까지의 거리 > 표준편차 * x (x=2~4)
- 값이 z +- 2~4 사이에 존재하면 평균에서 굉장히 벗어났으므로 이상치
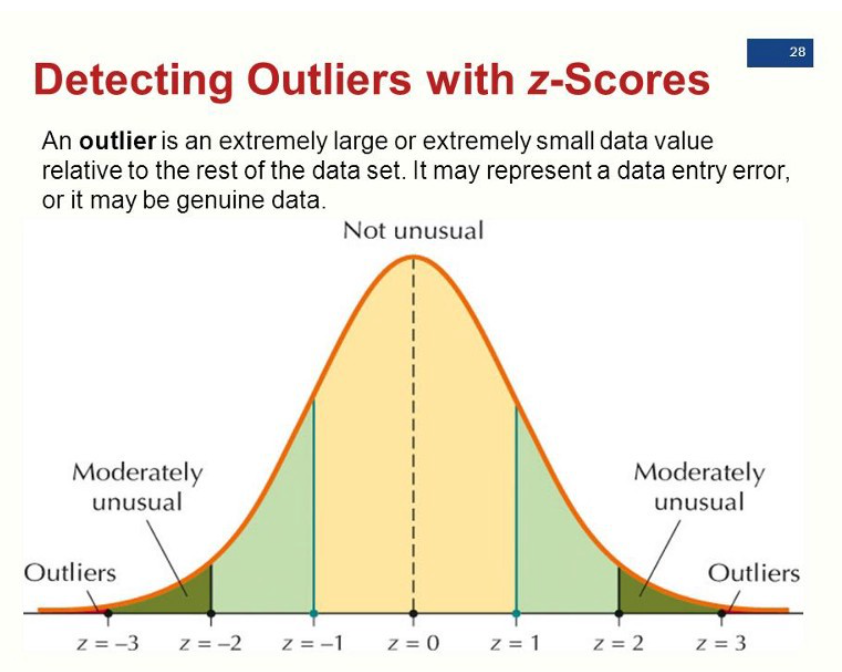
백분위수 이용
- 데이터 분포의 95% 바깥에 있는 값이면 이상치
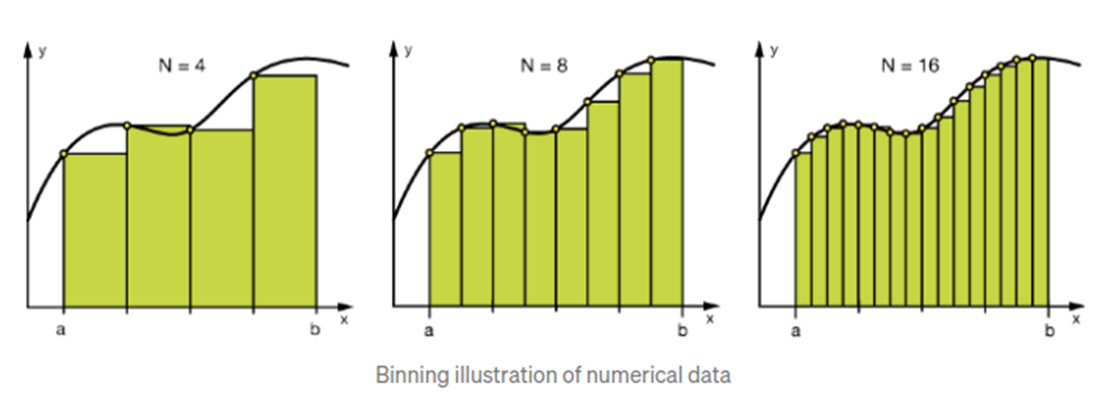
Binnig
- 데이터를 구간값(범주형)으로 변환
- 수치형 데이터을 범주화 / 범주형 데이터를 더 적은 범위로 축소
- 모델을 더 robust 하게 만들고 오버피팅 방지 (특정 데이터에 특화되어 있거나 민감하지 않고 고루고루 데이터의 대표성을 잘 반영)
- R 이나 Python에서 각 데이터의 히스토그램을 그려보고 구간값 조정 => 각 구간별로 데이터를 뽑아서 데이터셋을 재구성한 후 성능이 조금 좋아졌다는 후기가....!! by. 박사쌤
Log transform
- 로그 변환을 통해 한쪽으로 편향된(skewed) 데이터를 조정하여 정규분포와 가깝게 만들어준다.
- 편향된 데이터의 영향을 줄여주고 모델을 보다 robust 하게 만들어준다.
- 로그를 씌우기 때문에 데이터가 양수로 이루어져 있어야 하므로 통상 log(x+1) 수식을 이용한다.
- Regression 모델은 애초에 정규분포를 가정하기 때문에 로그 변환의 필요성이 있다.
- 편향이 심하다고 판단하는 기준은 +-3 ~ 4 정도인 것 같다. (조금씩 다름)
- 인위적으로 데이터를 변형하기 때문에 특징 해석이 어려워질 수 있다. (예를 들어 키 데이터인데 로그변환을 통해 값이 대폭 작아지면 이게 키 데이터인지 뭔지 파악 어려움)
One-hot encoding
Feature split
- 하나의 feature 를 분리 ex) 2022년 10월 22일 => 년도별 데이터, 월별 데이터, 일별 데이터 3가지로 분리
Scaling
Normalization
- 데이터 값을 0~1 사이로 변환해 값의 규모를 줄여줌.
- min/max 편차가 심하거나 다른 열에 비해 데이터의 크기가 큰 경우 사용
- 데이터의 scale 을 비슷하게 맞춰줌으로서 데이터가 비슷한 중요도를 갖도록 학습
- 머신러닝에서는 더 작은 scale을 갖는 데이터가 더 빠르게 수렴하면서 학습 성능 향상에 도움을 준다
Standardization
- z-score가 +- 2를 넘는 값들을 지워 평균에서 크게 벗어난 이상치를 제거
- KNN, KMEANS, SVM 같은 거리 기반 모델은 필수
Weighting
- 중요한 feature의 영향력을 높여주는 방법
- 데이터값을 단순 제곱 하거나 SQRT 해줌 => correlation 높아지는 변수에 적용
- Regression, Tree 모델에 효과 있음
Feature engineering tools
- Feature Engineering 작업을 알아서 해주는 tool 이 있다네?!
- feature selection / feature construction / 관계형 데이터베이스를 사용해 새로운 feature 생성 등
https://www.kaggle.com/code/willkoehrsen/automated-feature-engineering-basics/notebook
Automated Feature Engineering Basics
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
https://github.com/alteryx/featuretools/
'인공지능(AI) & 데이터 분석' 카테고리의 다른 글
| [Feature Engineering] Feature Selection & evaluation (0) | 2022.11.23 |
|---|---|
| [CNN/이미지처리] 데이터 증강(Data Augmentation) (0) | 2022.04.14 |
| [DNN] 인공신경망/딥러닝 (Deep Neural Network) (0) | 2022.04.14 |
| 논문 (빨리)(효율적으로) 읽는 법 *다시 정리 예정 (0) | 2022.03.11 |
💡 좋은 모델 개발은 좋은 데이터에서 비롯된다.
아무리 좋은 알고리즘을 사용하고 갖은 노력을 들여도 데이터가 쓰레기면 결코 좋은 성능은 기대하기 힘들다.
Imputation
- 결측치(NA) 값은 머신러닝 모델 성능에 영향을 줌
- 70% 이상의 결측치가 있는 행과 열은 지워주는 것도 좋다
- Numerical Imputation (수치형 데이터)
- 결측치를 0 이나 중앙값으로 대체 - Categorical Imputation (범주형 데이터)
- 가장 많이 발생한 값으로 대체
- 아예 새로운 범주로 대체 - Random sample Imputation
-데이터셋에서 임의로 뽑은 값으로 대체 - End of Distribution Imputation
-mean(평균) + 3*std(분산) 으로 대체
- 결측치를 outlier(이상치)로 보냄
- 영향을 최소화 하기 위해서라면 오히려 보편적을 값을 사용하지만 결측치 자체에 특별한 의미를 부여하거나 이상치 후처리를 위해서 수행하는 작업이 아닐까라는 개인적인 판단
Outlier
- 평균적인 값보다 많이 동떨어진 데이터
- 대게 Boxplot 을 그려 파악
- 모델에 따라 민감도 다름 (모델에 따라 이상치를 포함할지 제거할지 조정할지 정함)
표준편차 이용
- 값과 평균까지의 거리 > 표준편차 * x (x=2~4)
- 값이 z +- 2~4 사이에 존재하면 평균에서 굉장히 벗어났으므로 이상치
백분위수 이용
- 데이터 분포의 95% 바깥에 있는 값이면 이상치
Binnig
- 데이터를 구간값(범주형)으로 변환
- 수치형 데이터을 범주화 / 범주형 데이터를 더 적은 범위로 축소
- 모델을 더 robust 하게 만들고 오버피팅 방지 (특정 데이터에 특화되어 있거나 민감하지 않고 고루고루 데이터의 대표성을 잘 반영)
- R 이나 Python에서 각 데이터의 히스토그램을 그려보고 구간값 조정 => 각 구간별로 데이터를 뽑아서 데이터셋을 재구성한 후 성능이 조금 좋아졌다는 후기가....!! by. 박사쌤
Log transform
- 로그 변환을 통해 한쪽으로 편향된(skewed) 데이터를 조정하여 정규분포와 가깝게 만들어준다.
- 편향된 데이터의 영향을 줄여주고 모델을 보다 robust 하게 만들어준다.
- 로그를 씌우기 때문에 데이터가 양수로 이루어져 있어야 하므로 통상 log(x+1) 수식을 이용한다.
- Regression 모델은 애초에 정규분포를 가정하기 때문에 로그 변환의 필요성이 있다.
- 편향이 심하다고 판단하는 기준은 +-3 ~ 4 정도인 것 같다. (조금씩 다름)
- 인위적으로 데이터를 변형하기 때문에 특징 해석이 어려워질 수 있다. (예를 들어 키 데이터인데 로그변환을 통해 값이 대폭 작아지면 이게 키 데이터인지 뭔지 파악 어려움)
One-hot encoding
Feature split
- 하나의 feature 를 분리 ex) 2022년 10월 22일 => 년도별 데이터, 월별 데이터, 일별 데이터 3가지로 분리
Scaling
Normalization
- 데이터 값을 0~1 사이로 변환해 값의 규모를 줄여줌.
- min/max 편차가 심하거나 다른 열에 비해 데이터의 크기가 큰 경우 사용
- 데이터의 scale 을 비슷하게 맞춰줌으로서 데이터가 비슷한 중요도를 갖도록 학습
- 머신러닝에서는 더 작은 scale을 갖는 데이터가 더 빠르게 수렴하면서 학습 성능 향상에 도움을 준다
Standardization
- z-score가 +- 2를 넘는 값들을 지워 평균에서 크게 벗어난 이상치를 제거
- KNN, KMEANS, SVM 같은 거리 기반 모델은 필수
Weighting
- 중요한 feature의 영향력을 높여주는 방법
- 데이터값을 단순 제곱 하거나 SQRT 해줌 => correlation 높아지는 변수에 적용
- Regression, Tree 모델에 효과 있음
Feature engineering tools
- Feature Engineering 작업을 알아서 해주는 tool 이 있다네?!
- feature selection / feature construction / 관계형 데이터베이스를 사용해 새로운 feature 생성 등
https://www.kaggle.com/code/willkoehrsen/automated-feature-engineering-basics/notebook
Automated Feature Engineering Basics
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
https://github.com/alteryx/featuretools/
'인공지능(AI) & 데이터 분석' 카테고리의 다른 글
| [Feature Engineering] Feature Selection & evaluation (0) | 2022.11.23 |
|---|---|
| [CNN/이미지처리] 데이터 증강(Data Augmentation) (0) | 2022.04.14 |
| [DNN] 인공신경망/딥러닝 (Deep Neural Network) (0) | 2022.04.14 |
| 논문 (빨리)(효율적으로) 읽는 법 *다시 정리 예정 (0) | 2022.03.11 |