
AAC (안드로이드 아키텍쳐 컴포넌트)를 접하면서 자연스럽게 아키텍쳐에 대해 공부하고 싶다는 생각이 들었다.
무지성으로 사용했던 Repository 나 LiveData 의 사용 이유부터 여러 블로그와 깃헙들을 떠돌며 눈팅했던 코드들의 foldering 구조에서 보이는 미묘한 공통점에 대해서도 의문을 가지게 되면서 유기적으로 안드로이드 권장 아키텍쳐에 대해 공부할 수 밖에 없었던 것 같다.
💡 왜 공식 권장 아키텍쳐를 사용하는가?
사용자의 모바일 환경은 굉장히 유동적이다.
예를 들어 사용자가 SNS앱에서 사진을 업로드 하기 위해 사진 촬영을 하거나 앨범에 접근할 땐 카메라, 앨범 앱이 실행되면서(직접 구현하지 않는 이상...) 기존의 앱이 중단된다. 또 그러다 갑자기 전화가 울리면 사용자는 잠시동안 전화 통화 후 카메라 앱으로 돌아가 사진을 찍고 다시 SNS 앱으로 돌아간다.
이렇게 사용자가 의도했던 하지않았던 모바일앱에서 사용자 환경은 생각보다 자주 중단된다.
이때 앱의 사용자 환경이 중단되었다가 다시 이어지더라도 원래의 사용자 환경은 잘 유지 되어야 하고 그러기 위해서는 각각의 사용자 활동이 개별적이고 비순차적으로 실행되어야 하는 이슈가 생긴다. 그러기 위해서는 앱의 각 구성요소(액티비티, 프래그먼트, Service, Content Provider, broadcast reciever)들이 서로 종속되어 있어서는 안되며 앱 구성요소가 앱 데이터나 상태를 저장하고 있어서는 안된다.
하지만 앱 구성요소에 데이터를 저장하지 않으면 어떻게 해야 할까?
동시에 앱의 확장성과 유지보수를 고려해야 하고 더 쉽게 테스트 할 수 있도록 설계해야 한다.
이러한 이슈를 해결하기 위해 안드로이드에서 권장하는 아키텍쳐 설계 방법은 다음과 같다.
- 관심사 분리 : 액티비티와 프래그먼트에 모든 코드를 다 넣지 말아라. 액티비티나 프래그먼트는 다들 알다시피 화면에 뷰를 그리는 UI 기반의 클래스이다. 따라서 UI 관련 코드나 운영체제와 상호작용을 처리하는 로직만 포함하는 것이 좋다.
- 데이터 모델에서 UI 도출하기 : 화면에 보여질 UI를 먼저 정한 다음 어떤 데이터들이 필요할지를 정하는 것이 아니라 앱에서 어떤 데이터를 사용하고, 어떻게 처리할지를 먼저 정의한 다음 (이것을 데이터 모델 구축이라고 하는듯...) UI 를 도출하라는 의미 같다.
- 단일 소스 저장소 : 특정 데이터 유형마다 단일 소스 저장소(SSOT)를 할당해야 한다. 즉, 같은 유형의 데이터는 한 곳에 일원화하여 관리해야 하고 다른 유형의 데이터가 접근할 수 없다.
- 단방향 데이터 흐름 : 데이터나 상태의 변화는 데이터소스 -> UI, 사용자 이벤트는 UI -> SSOT로 흘러야 한다.
✔️ 2020년까지의 공식 권장 아키텍쳐
위와 같은 이슈와 권장 설계 방법을 고려하여 구조화한 아키텍쳐가 바로 아래와 같은 그림이다.
2020년까지 공식문서에 안내되어 있었고 내가 처음 접했던 안드로이드 공식 권장 아키텍쳐였다.

Activity/Fragment
- UI 화면 갱신과 사용자 입력과 같은 이벤트를 받아들인다
- ViewModel의 LiveData를 옵져빙 하여 데이터의 갱신이 관찰되면 화면 UI를 갱신한다
- 자신이 관찰할 ViewModel을 알고, 관찰해야 하므로 ViewModel에 종속적이다 (*MVVM 패턴에서는 데이터바인딩을 사용해 이 종속성을 끊어낸다)
ViewModel
- View가 화면에 데이터를 표시하고 갱신할 수 있도록 데이터를 저장하고 관리한다
- 사용자가 데이터 갱신을 요청하면 Repository에 요청하여 데이터를 받아오기 때문에 Repository에 종속적이다
- LiveData를 사용해 데이터를 관리한다. ViewModel에 선언된 데이터이므로 액티비티나 프래그먼트가 완전히 finish 되기 전까지 유지되기 때문에 화변 전환 등의 화면 재생성에도 데이터가 유지된다
- ViewModel은 View를 알지 못한다. 그저 자신은 특정 유형의 데이터들을 관리할 뿐이다. 그렇기 때문에 여러 뷰에서 같은 유형의 데이터들을 필요로 하면 여러 뷰가 하나의 뷰모델을 사용할 수도 있다
Repository
- ViewModel에서 직접 Retrofit 등을 사용해 백엔드에 접근하는 것보다 유지보수와 관심사 분리 원칙에 따라 Repository라는 data layer 계층을 만들어 사용한다 (즉, 요청받은 데이터를 호출하는 역할을 한다)
- 공식문서 예제에서는 Repository에서 바로 백엔드와 통신하는 WebService를 호출해 사용하도록 작성되어 있지만 데이터를 local database를 통해 가져올건지 외부 network를 통해 가져올건지에 따라 Model, Remote Data Source 등의 하위 계층을 만들어 거쳐가도록 설계한다 -> 이렇게 설계하는 경우 다시 한 번 model, remoteDataSource를 호출해 간접적으로 데이터를 호출하게 된다
- 보통 데이터 유형별로 repository를 따로 만든다 (UserRepository, PhotoRepository)
- 필요에 따라 Reposotory를 인터페이스화 하여 구현할 수 있다
class MapRepository(private val remoteDataSource: RemoteDataSourceImp) {
suspend fun getPhotoSpots(latitude:Double, longitude:Double, scope:Int, is_select:Boolean) : List<PhotoSpotsDTO> {
return remoteDataSource.getPhotoSpots(latitude,longitude,scope,is_select) //굳이 is_select 줄 필요가 없을듯?,,,
}
suspend fun getPhotoSpotInfo(photoSpotId : Int, latitude:Double,longitude:Double) : PhotoSpotItemDTO {
return remoteDataSource.getPhotoSpotInfo(photoSpotId,latitude,longitude)
}
}class UserRepository(private val remoteDataSource: RemoteDataSourceImp) {
suspend fun requestLogin(auth_code:String) : LoginDTO {
return remoteDataSource.requestLogin(auth_code)
}
suspend fun requestLogout(access_token: String) {
return remoteDataSource.requestLogout(access_token)
}
}Model
- 로컬 데이터베이스를 통해 데이터를 가져올 때 호출되는 계층 (사용해본적이 없어서 아직 잘 모르겠다)
- Room 라이브러리를 사용해 앱 내부에 데이터베이스를 구축하고 SQL 쿼리문을 사용해 데이터를 추출하도록 하도록 설계 하는 것 같다
- 테이블 설계시 Entity, 쿼리문 작성시 Room DAO, 데이터베이스 구축시 Room database를 사용하는 것 같다.
Remote Data Source
- 외부 network를 통해 데이터를 가져올 때 백엔드와 통신하는 WebService를 실제로 호출하는 계층이다
- 보통 인터페이스화 하여 구현해 사용한다. 왜 그렇게 사용하는지 아직 실전에 적용해본 적이 없어 정확하지는 않지만 백엔드와 통신하기 위해 프로토콜이나 사용할 라이브러리에 따라 다양하게 구현할 수도 있기 때문에 그런 것으로 생각하고 있다
// 굳이 인터페이스화 해버림...ㅎㅎ
interface RemoteDataSource {
//포토가이드
suspend fun getPhotoGuides() : List<PhotoGuidesDTO>
suspend fun getDetailPhotoGuide(photoGuideId : Int) : PhotoGuideItemDTO
//포토맵
suspend fun getPhotoSpots(latitude:Double, longitude:Double, scope:Int, is_select:Boolean) : List<PhotoSpotsDTO>
suspend fun getPhotoSpotInfo(photoSpotId : Int, latitude:Double,longitude:Double) : PhotoSpotItemDTO
//로그인,인증
suspend fun requestLogin(auth_code: String) : LoginDTO
suspend fun requestLogout(access_token: String)
//포토가이드 만들기
}// RetrofitInstance를 싱글톤으로 만들었고 그 안에 백엔드와 통신하는 WebService를 생성
class RemoteDataSourceImp(private val apiClient : RetrofitInstance) : RemoteDataSource{
override suspend fun getPhotoGuides(): List<PhotoGuidesDTO> {
return apiClient.api.getAllPhotoGuide()
}
override suspend fun getDetailPhotoGuide(photoGuideId : Int): PhotoGuideItemDTO {
return apiClient.api.getDetailPhotoGuide(photoGuideId)
}
override suspend fun getPhotoSpots(latitude:Double, longitude:Double, scope:Int, is_select:Boolean): List<PhotoSpotsDTO> {
return apiClient.api.getPhotoSpots(latitude, longitude, scope,true) //is_select
}
override suspend fun getPhotoSpotInfo(photoSpotId : Int, latitude:Double,longitude:Double): PhotoSpotItemDTO {
return apiClient.api.getPhotoSpotInfo(photoSpotId,latitude,longitude)
}
override suspend fun requestLogin(auth_code : String) : LoginDTO {
return apiClient.api.requestLogin(auth_code)
}
override suspend fun requestLogout(access_token: String) {
return apiClient.api.logout(access_token)
}
}
💡 의존성 주입??....
class ViewModelFactory(private val remoteDataSource : RemoteDataSourceImp): ViewModelProvider.Factory {
// 액티비티 별로 서로 다른 뷰모델을 만들기 위해서 ViewModelProvider.Factory 를 implements 함
// 뷰모델을 만드는 create() 메서드를 오버라이딩
override fun <T : ViewModel> create(modelClass: Class<T>): T {
return when {
modelClass.isAssignableFrom(MapViewModel::class.java) -> {
val repository = MapRepository(remoteDataSource)
MapViewModel(repository) as T
}
modelClass.isAssignableFrom(HomeViewModel::class.java) -> {
val repository = UserRepository(remoteDataSource)
UserViewModel(repository) as T
}
else -> {
throw IllegalArgumentException("Failed to create ViewModel : ${modelClass.name}")
}
}
}
}
뷰모델 팩토리를 사용해 뷰모델을 생성할 때 매번 같은 remoteDataSourceImp를 뷰모델에 넘겨주는 코드를 작성하게 되었다. remoteDataSourceImp를 다양하게 구현하게 사용한 것이 아닌 같은 기능을 하는 객체를 여러번 생성해 사용하는 것은 낭비이기 때문에 이런 재사용성 문제를 해결하기 위해 Hilt 와 같은 의존성 주입(DI) 기술을 사용하는 것 같다. (이건 다른 포스팅에서 다뤄보도록 하겠다)
어떤가? 권장 설계 방법에 따라 화면 갱신, 데이터 관리, 데이터 호출 등의 관심사를 분리했고, UI -> Data 단방향으로 흘러가면서 각각의 계층이 바로 하위 계층에만 종속되어 있다. 뷰는 데이터를 어떻게 불러오는지 몰라도 되고, 뷰모델은 뷰를 모르며 repository를 통해 데이터를 요청하지 어떤 라이브러리를 사용해 어떻게 백엔드에 접근하는지 알지 못한다.
✔️ 2022년까지의 공식 권장 아키텍쳐
하지만 2022년 이후로 권장 아키텍쳐가 수정되었다. (미리 알았으면 좋았을걸...왜 난 이렇게 한 발 느릴까..)

UI Layer(Presentation Layer)
- 데이터 레이어에서 가져오는 애플리케이션 데이터를 UI 에 적절하게 표시
- 데이터에 변경사항이 있다면 변경사항 또한 갱신해줘야 함
- 기존 아키텍쳐의 뷰와 뷰모델 역할과 거의 동일
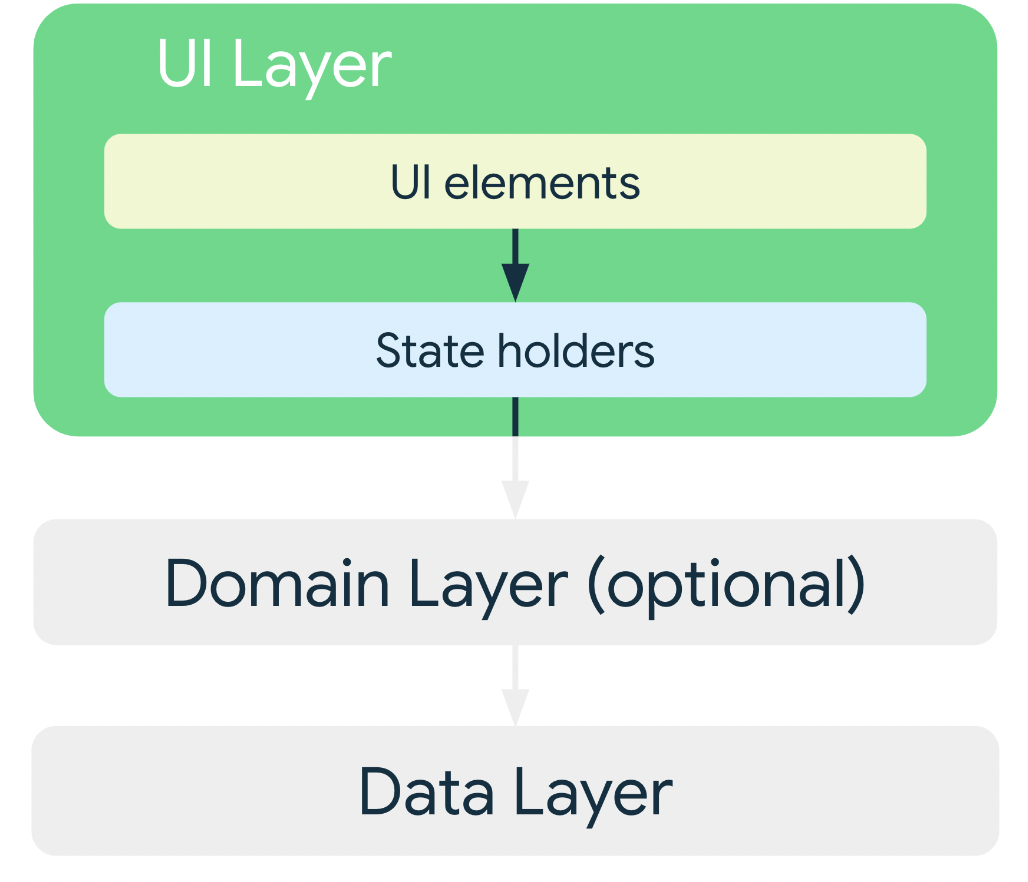
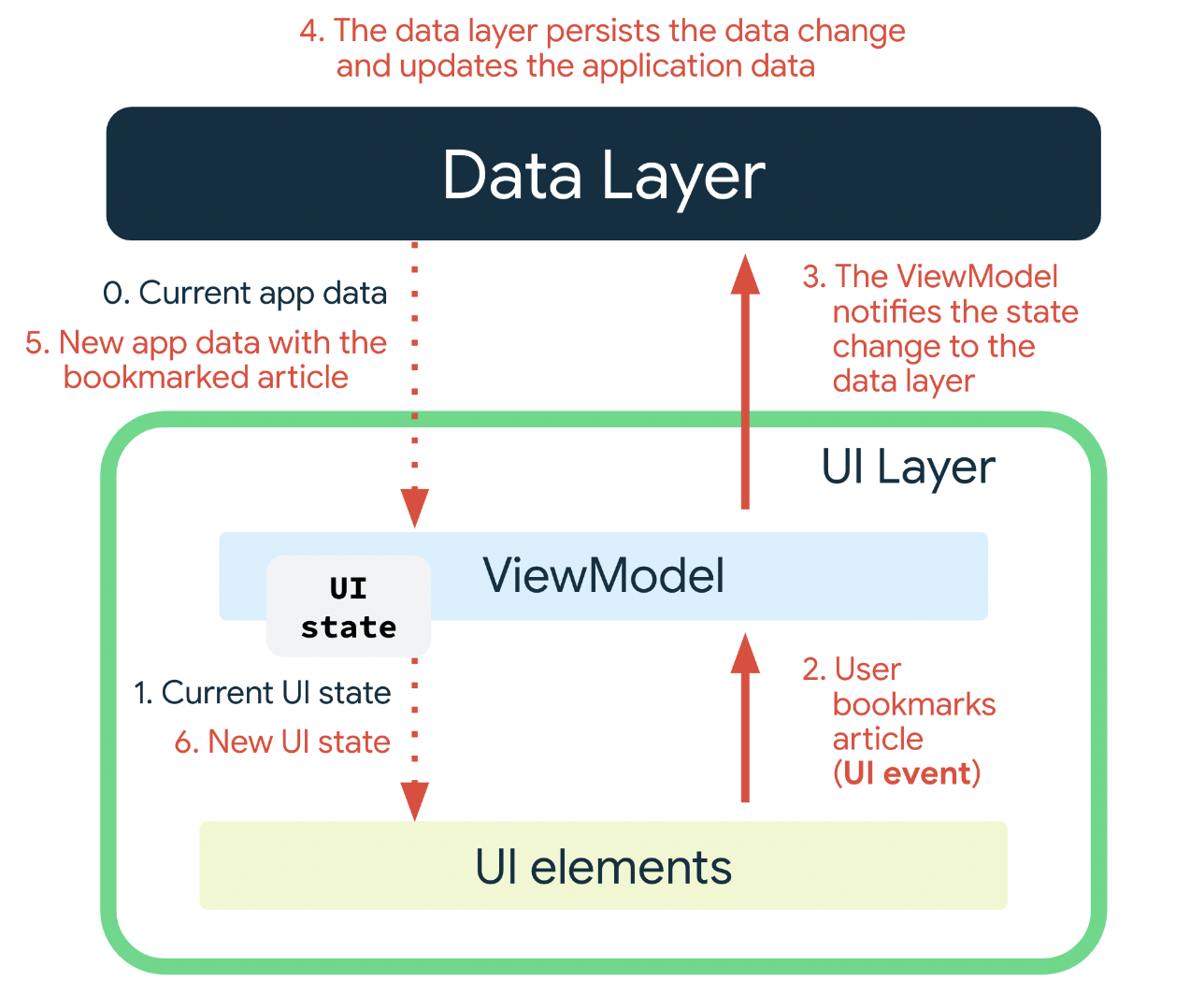
UI elements
- 화면에 데이터를 렌더링하는 UI 요소, View나 Jetapck Compose 함수를 사용하여 빌드할 수 있다 (요즘은 Compose 사용 강조)
- 생명주기에 종속되는 UI 로직을 처리 (ex. 사용자 버튼 클릭 이벤트 로직)
State Holders
- 데이터를 보유하고 화면 UI에 보여주는 로직을 처리, 대표적으로 ViewModel
- 데이터 클래스(이름 짓는법; 기능 + UiState)에 데이터의 상태(속성)을 정의하고 이것을 뷰모델에서 저장하고 관리한다
- 뷰모델에서 데이터상태를 생성한다고 나와 있는데 그냥 data layer로부터 데이터 요청해 받아서 초기화 하고 갱신하는걸 말함
- LiveData 외에 StateFlow 와 같이 관찰 가능한 데이터 홀더에 데이터를 저장 -> UI element에서 관찰
- 생명주기에 종속되지 않는 비지니스 로직(데이터 요청 및 전처리)과 화면 UI 상태(갱신된 데이터를 칭함)를 처리
class NewsViewModel(...) : ViewModel() {
val uiState: StateFlow<NewsUiState> = …
}class NewsActivity : AppCompatActivity() {
private val viewModel: NewsViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
...
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.uiState.collect {
// Update UI elements
}
}
}
}
}LiveData의 경우 observe() 메서드를 사용하지만 Kotlin Flow의 경우 collect() 메서드를 사용하는 것 같다. (Flow는 추후 자세히...)
LiveData를 사용할 때는 LifecycleOwner가 자동으로 생명주기를 처리해줬는데 Flow를 사용하면 적절한 코루틴 scope 과 repeatOnLifecycle API로 처리하는 것이 좋다고 한다.... (더 복잡하고 까다로워 보이는데 왜 쓰는걸까... 🤔)
Data Layer

Repositories
- 0개부터 여러 개의 Data Source를 각각 포함할 수 있는 저장소 (이름짓는법; 데이터 유형 + 저장소)
- 기능별로 Repository를 만들어 사용한다 (UserRepository, MovieRepository)
- 반드시 Repository를 통해서만 데이터에 접근해야 한다(UI 레이어나 Domain레이어가 데이터 소스에 직접 접근해서는 절대 안 됨!!)
- 종속 항목 삽입 권장사항에 따라 Repository는 Data Source를 생성자의 종속 항목으로 사용 (아직 몬소린지 잘 몰겠음~)
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Data Sources
- 아키텍쳐에서 local, remote별로 나누어 사용했던 것처럼 파일, 네트워크, 로컬 데이터베이스 등 여러개의 데이터소스를 만들어 사용할 수 있다. 하지만 반드시 한 데이터소스는 하나의 데이터 유형만을 다뤄야 한다. (파일 데이터소스에서 네트워크 데이터소스 다루면 안됨!!)
- 하나의 repository가 다른 repository에 포함되는 경우도 있을 수 있다. 사용자에 대한 reository가 있고 그 아래 사용자 로그인/회원가입에 필요한 데이터를 다루는 repository를 각각 만들어 더 세분화하여 관리하는 것이다.
Domain Layer
- 복잡한 비지니스 로직이나 여러 ViewModel에서 재사용되는 로직을 하나의 Usecase 클래스로 만들어 관리하는 계층
- 예를 들어 여러 repository에서 데이터를 가져와 결합하고 가공해 화면에 표시해야 한다고 하면 다소 복잡한 비지니스 로직이 됨으로 뷰모델에서 처리하기에는 부담이 될 수 있기 때문에 사용한다
사실 22년 이전 구조에서 완전히 새로운 구조가 나왔다기 보다는 각 계층을 좀 더 하나의 layer로 통일시키려고 한 것 같다. 또 내가 느끼기에는 좀 더 다형성이나 분리 원칙을 강조하는 방식으로 공식문서의 설명이 작성된 것 같다. 그러면서 은근히 Compose 를 사용하라고 강조하는 것도 잊지 않는....ㅋㅋ
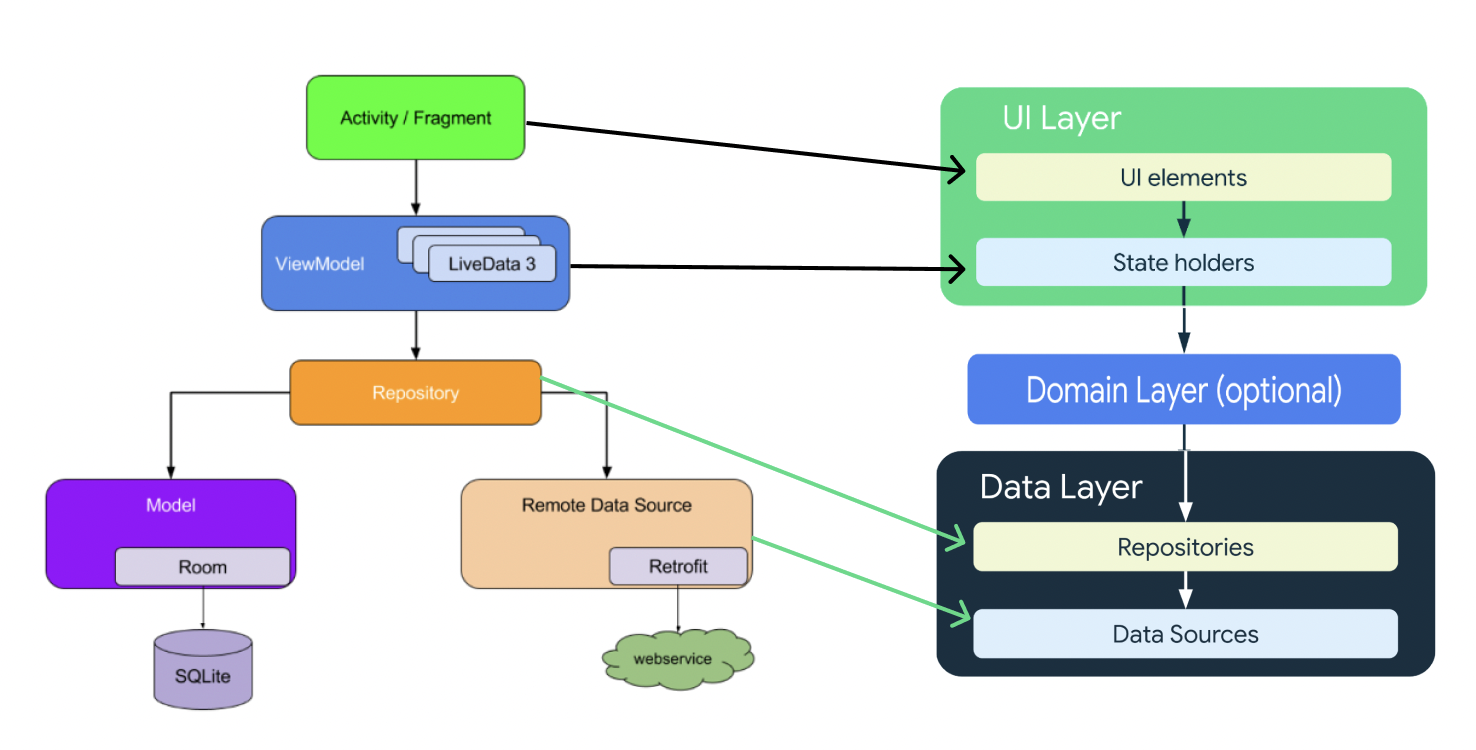
또한 UI 레이어를 프레젠테이션 레이어라고도 명명하는 것을 봐서는 클린 아키텍쳐와 유사한 구조로 가겠다고 대놓고 선언하는 것 같다.

[참고자료]
https://developer.android.com/topic/architecture?hl=ko
앱 아키텍처 가이드 | Android 개발자 | Android Developers
앱 아키텍처 가이드 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 가이드에는 고품질의 강력한 앱을 빌드하기 위한 권장사항 및 권장 아키텍처가 포함
developer.android.com
[Android] Repository Pattern
디자인 패턴을 살펴보던 도중, Repository Pattern을 적용해본적은 있지만 정리를 하지 않았던 것을 발견하여 간단하게 정리를 하면서 글을 작성해보고자 한다. Clean Architecture 예제를 확인해보면 repos
heegs.tistory.com
😇 안드로이드 권장 아키텍처에 대해서 (MVVM 패턴과 비슷!)
필자는 안드로이드 개발 및 관련 공부를 약 1년 반 정도 해왔습니다..! 우연한 기회로 접하게 된 안드로이드 개발이였지만 필자의 개발 적성과 성향에 잘 맞아 꾸준히 공부하고 있습니다 ㅎㅎ이
velog.io
[Android] 앱 아키텍처 가이드의 권장 앱 아키텍처가 변경되었다?!
내용이!!!! 바뀌었다!!!!!!!!!!!
velog.io
'Android' 카테고리의 다른 글
| [안드로이드/DI] 의존성 주입(DI) & Hilt 시작해보기! (0) | 2024.01.09 |
|---|---|
| [안드로이드/AI] 앱에서 Segmentation 모델을 사용하기 위한 다양한 시도 (0) | 2023.08.17 |
| [안드로이드/아키텍쳐] AAC ViewModel 사용하기 (0) | 2023.07.13 |
| [안드로이드/아키텍쳐] MVC, MVVM 패턴 그리고 ViewModel (0) | 2023.07.13 |
| [안드로이드/Activity] Parcelable, Serializable 그리고 Parcelize (1) | 2023.07.13 |